Brief Introduction to Profiling
Let's start with a quick introduction to what profiling is. Profiling is a run-time program analysis technique. Generally, a certain level of instrumentation is required to retrieve some kind of tracing information while the program is running. This is usually in the form of tracing instructions interleaved with the line of your source code, like debug statements, for instance, usually enriched with timestamp information or other relevant details, like memory usage, etc... .
One normally distinguishes between two main categories of profilers:
- event-based (or deterministic)
- statistical (or sampling).
Profilers in the first category make use of hooks that allow registering event callbacks. At the lowest level, these hooks are provided directly by the operating system and allow you to trace events like function calls and returns. Virtual machines and interpreters, like JVM and CPython, provide software hooks instead, for generally the same events, but also for language-specific features, like class loading for instance. The reason why profilers in this category are called deterministic is that, by listening to the various events, you can get a deterministic view of what is happening inside your application.
In contrast, statistical profilers tend to provide approximate figures only, obtained by, e.g., sampling the call stack at regular interval of times. These samples can then be analysed statistically to provide meaningful metrics for the profiled target.
One might get the impression that deterministic profilers are a better choice than statistical profilers. However, both categories come with pros and cons. For example, statistical profilers usually require less instrumentation, if none at all, and introduce less overhead in the profiled target program. Therefore, if a statistical profiler can guarantee a certain accuracy on the metrics that can be derived from them, then it is usually a better choice over a more accurate deterministic profiler that can introduce higher overhead.
Python Profiling
There are quite a plethora of profiling tools available for Python, either deterministic or statistical. The official documentation describes the use of the Python profiling interface through two different implementations:
The former is a pure Python module and, as such, introduces more overhead than
the latter, which is a C extension that implements the same interface as
profile. They both fit into the category of deterministic profilers and make
use of the Python C API
PyEval_SetProfile
to register event hooks.
Standard Python Profiling
Let's have a look at how to use cProfile, as this will be the standard choice
for a deterministic profiler. Here is an example that will profile the
call-stack of psutil.process_iter.
# File: process_iter.py
import cProfile
import psutil
cProfile.run(
'[list(psutil.process_iter()) for i in range(1_000)]',
'process_iter'
)
The above code runs psutil.process_iter for 1000 times through cProfile and
sends the output to the process_iter file in the current working directory. A
good reason to save the result to a file is that one can then use a tool like
gprof2dot to provide a graphical
representation of the collected data. This tool turns the output of cProfile
into a dot graph which can then be visualised to make better sense of it. E.g.,
these are the commands required to collect the data and visualise it in the form
of a DOT graph inside a PDF document:
python3 process_iter.py
gprof2dot -f pstats process_iter | dot -Tpdf -o process_iter.pdf
This is what the result will look like. The colours help us identify the branches of execution where most of the time is spent.

A Look Under the Bonnet
The output of a tool like gprof2dot can be quite intuitive to understand, especially if you have had some prior experience with profilers. However, in order to better appreciate what is still to come it is best if we have a quick look at some of the basics of the Python execution model.
Python is an interpreted language and the reference implementation of its interpreter is CPython. As the name suggests, it is written in C, and it offers a C API that can be used to write C extensions.
One of the fundamental objects of CPython is the interpreter itself, which has a
data structure associated with it, namely PyInterpreterState. In principle,
there can be many instances of PyInterpreterState within the same process, but
for the sake of simplicity, we shall ignore this possibility here. One of the
fields of this C data structure is tstate_head, which points to the first
element of a doubly-linked list of instances of the PyThreadState structure.
As you can imagine, this other data structure represents the state of a thread
of execution associated with the referring interpreter instance. We can navigate
this list by following the references of its field next (and navigate back
with prev).
Each instance of PyThreadState points to the current execution frame, which is
the object that bears the information about the execution of a code block via
the field frame. This is described by the PyFrameObject structure, which is
also a list. In fact, this is the stack that we are after. Each frame will have,
in general, a parent frame that can be retrieved by means of the f_back
pointer on the PyFrameObject structure. The picture produced by gprof2dot of
the previous section is the graphical representation of this stack of frames.
The information contained in the first row of each box comes from the
PyCodeObject structure, which can be obtained from every instance of
PyFrameObject via the f_code field. In particular, PyCodeObject allows you
to retrieve the name of the file that contains the Python code being executed in
that frame as well as its line number and the name of the context (e.g. the
current function).
Sometimes the C API changes between releases, but the following image is a fairly stable representation of the relations between the above-mentioned structures that are common among many of the major CPython releases.

The loop around PyFrameObject, which represents its field f_back, creates
the structure of a singly-linked list of frame objects. This is precisely the
frame stack.
The Python profiling API can be demonstrated with some simple Python code. The
following example declares a decorator, @profile, that can be used to extract
the frame stack generated by the execution of a function. In this case, we
define the factorial function
import sys
def profile(f):
def profiler(frame, event, arg):
if "c_" in event:
return
stack = []
while frame:
code = frame.f_code
stack.append(f"{code.co_name}@{frame.f_lineno}")
frame = frame.f_back
print("{:12} {}".format(event.upper(), " -> ".join(stack[::-1])))
def wrapper(*args, **kwargs):
old_profiler = sys.getprofile()
sys.setprofile(profiler)
r = f(*args, **kwargs)
sys.setprofile(old_profiler)
return r
return wrapper
@profile
def factorial(n):
if n == 0:
return 1
return n * factorial(n-1)
if __name__ == "__main__":
factorial(3)
Note that the coding of the profiler function can be simplified considerably
by using the inspect module:
import inspect
...
def profiler(frame, event, arg):
if "c_" in event:
return
stack = [f"{f.function}@{f.lineno}" for f in inspect.stack()[1:]]
print("{:8} {}".format(event.upper(), " -> ".join(stack[::-1])))
...
Statistical Profiling
For a profiler from the statistical category, we have to look for external
tools. In this case, The "standard" approach is to make use of a system call
like setitimer, which is used to register a signal handler that gets called at
regular intervals of time. The general idea is to register a callback that gets
a snapshot of the current frame stack when triggered. An example of a profiler
that works like this is vmprof.
Some drawbacks of this approach are: 1. the signal handler runs in the same process as the Python interpreter, and generally the main thread; 2. signals can interrupt system calls, which can cause stalls in the running program.
There are other approaches that can be taken in order to implement a statistical
profiler, though. An example is pyflame,
which is more in the spirit of a debugging tool and uses ptrace-like system
calls. The situation is a bit more involved here since the profiler is now an
external process. The general idea is to use ptrace to pause the running
Python program, read its virtual memory and reconstruct the frame stack from it.
Here, the main challenges are 1. to find the location of the relevant CPython
data structures in memory and 2. parse them to extract the frame stack
information. The differences between Python 2 and Python 3 and the occasional
changes of the CPython ABI within the same minor release add up to the
complexity of the task.
Once all has been taken care of, though, a statistical profiler of this kind has the potential of lowering the overhead caused by source instrumentation even further so that the payoff is generally worth the effort.
Enter Austin
We just saw that with a tool like pyflame we can get away with no
instrumentation. An objection that can be raised against it, though, is that it
still halts the profiled program in order to read the interpreter state. System
calls like ptrace were designed for debugging tools, for which it is desirable
to stop the execution at some point, inspect memory, step over one instruction
or a whole line of source code at a time etc.... Ideally, we would like our
profiler to interfere as little as possible with the profiled program.
This is where a tool like Austin comes into play. Austin is, strictly speaking, not a full-fledged profiler on its own. In fact, Austin is merely a frame stack sampler for CPython. Concretely, this means that all Austin does is to sample the frame stack of a running Python program at (almost) regular intervals of time.
A similar approach is followed by py-spy, another Python profiler written in Rust and inspired by rbspy. However, Austin tends to provide higher performance in general for two main reasons. One is that it is written in pure C, with no external dependencies other than the standard C library. The other is that Austin is just a frame stack sampler. It focuses on dumping the relevant parts of the Python interpreter state as quickly as possible and delegates any data aggregations and analysis to external tools. In theory, Austin offers you higher sampling rates at virtually no cost at the expenses of the profiled process. This makes Austin the ideal choice for profiling production code at run-time, with not even a single line of instrumentation required!
So, how does Austin read the virtual memory of another process without halting
it? Many platforms offer system calls to do just that. On Linux, for example,
the system call is
process_vm_readv.
Once one has located the instance of PyInterpreterState, everything else
follows automatically, as we saw with the discussion on some of the details of
the CPython execution model.
On Your Marks
At this point you might have started, quite understandably, to be a bit concerned with concurrency issues. What can we actually make of a memory dump from a running process we have no control over? What guarantees do we have that the moment we decide to peek at the Python interpreter state, we find all the relevant data structures in a consistent state? The answer to this question lies in the difference in execution speed between C and Python code, the latter being, on average, order of 10 times faster than the former. So what we have here is a race between Austin (which is written in C) and the Python target. When Austin samples the Python interpreter memory, it does so quite quickly compared to the scale of execution of a Python code block. On the other hand, CPython is also written in C, can refresh its state pretty quickly too. As a cinematic analogy, think that we are trying to create an animation by taking snapshots of a moving subject in quick succession. If the motion we are trying to capture is not too abrupt (compared to the time it takes to take a snapshot, that is), then we won't spot any motion blur and our images will be perfectly clear. This video of the Cassini flyby over Jupiter, Europa and Io, for instance, been made from still images, visualises this idea clearly.
With Austin, each frame stack sample is the analogue of a snapshot and the moving subject is the Python code being executed by the interpreter. Of course, Austin could be unlucky and decide to sample precisely during the moment CPython is in the middle of updating the frame stack. However, based on our previous considerations, we can expect this to be a rather rare event. Sometimes a picture is worth a thousand words, so here is an idealistic "CPython vs Austin" execution timeline comparison.

Now one could argue that, in order to decrease the error rate, an approach
similar to pyflame, where we halt the execution before taking a snapshot, would
be a better solution. In fact, it makes practically no difference. Indeed it
could happen that the profiler decides to call ptrace while CPython is in the
middle of refreshing the frame stack. In this case, it doesn't really matter
whether CPython has been halted or not, the frame stack will be in an
inconsistent state anyway.
As a final wrap-up comment to this digression, statistical profilers for Python like Austin can produce reliable output, as the error rate tends to be very low. This is possible because Austin is written in pure C and therefore offers optimal sampling performance.
Flame Graphs with Austin
The simplest way to turn Austin into a basic profiler is to pipe it to a tool
like Brendan Gregg's FlameGraph.
For example, assuming that austin is in your PATH variable (e.g. because you
have installed it from the Snap Store with sudo snap install austin --beta
--classic) and that flamegraph.pl is installed in /opt/flamegraph, we can
do
austin python3 process_iter.py | /opt/flamegraph/flamegraph.pl --countname=usec > process_iter.svg
We are using --countname=usec because Austin samples frame stacks in
microseconds and this information will then be part of the output of the flame
graph tool. The following image is the result that I have got from running the
above command.
Austin is now included in the official Debian repositories. This means that you can install it with
apt install austin
on Linux distributions that are derived from Debian. On Windows, Austin can be installed from Chocolatey with the command
choco install austin --pre
Alternatively, you can just head to the release page on GitHub and download the appropriate binary release for your platform.
The TUI
The GitHub repository of Austin comes with a TUI application written in Python
and based on curses. It provides an example of an application that uses the
output from Austin to display live top-like profiling statistics of a running
Python program.
If you want to try it, you can install it with
pip install git+https://github.com/P403n1x87/austin.git
and run it with
austin-tui python3 /path/to/process_iter.py
By default, the TUI shows only the current frame being executed in the selected thread. You can navigate through the different threads with ⇞ Page Up and ⇟ Page Down. You can also view all the collected samples with the Full Mode, which can be toggled with F. The currently executing frame will be highlighted and a tree representation of the current frame stack will be available on the right-hand side of the terminal.
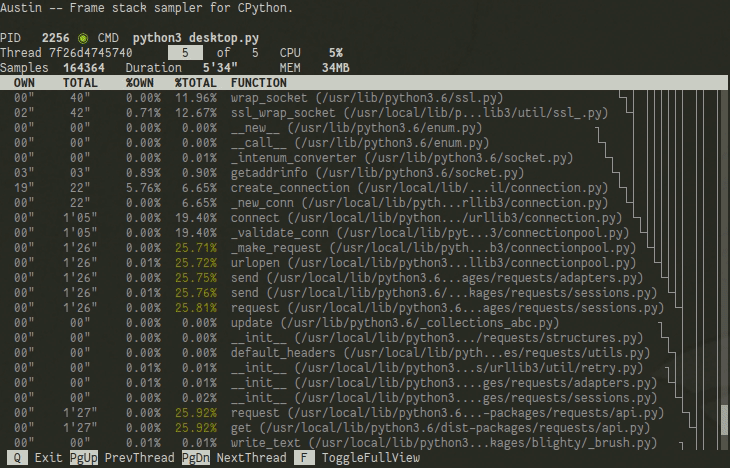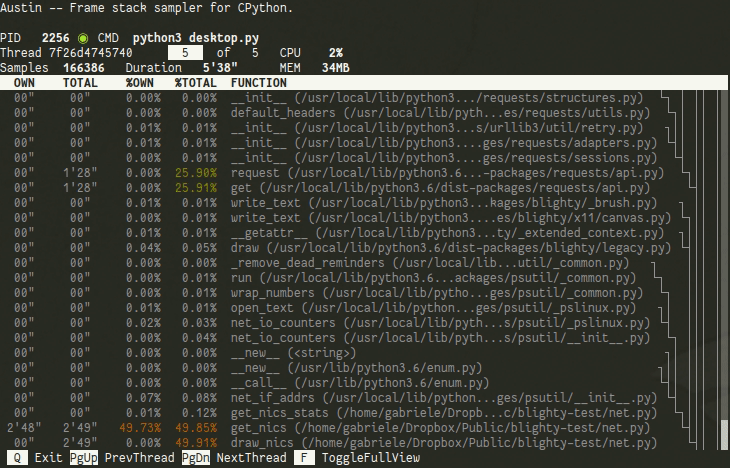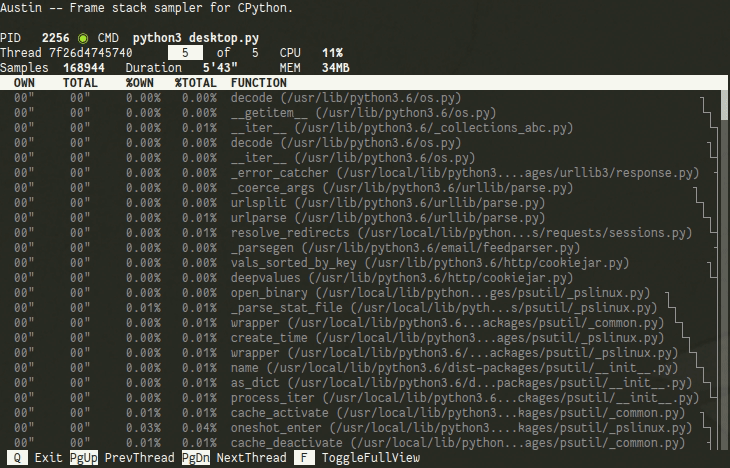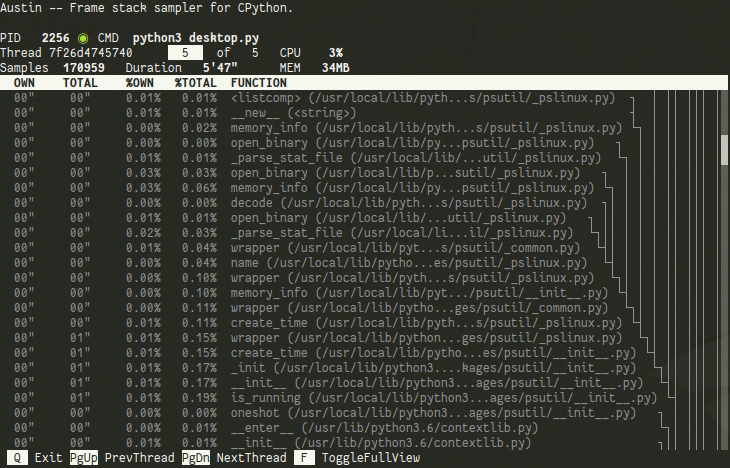
If you are a statistician or a data scientist working with Python, you can use the TUI to peek at your model while it is training to see what is going on and to identify areas of your code that could potentially be optimised to run faster. For example, let's assume that you are training a model on Linux in a single process using the command
python3 my_model.py
You can attach the TUI to your model with the command (as superuser)
austin-tui -p `pgrep -f my_model.py | head -n 1` -i 10000
The pgrep part is there to select the PID of the Python process that is
running your model, while -i 10000 sets the sampling interval to 10 ms.
Web Austin
Web Austin is another example of how to use Austin to build a profiling tool. In this case, we make use of the d3-flame-graph plugin for D3 to produce a live flame graph visualisation of the collected samples inside a web browser. This opens up to remote profiling, as the web application can be served on an arbitrary IPv4 address.
Like the TUI, Web Austin can be installed from GitHub with
pip install git+https://github.com/P403n1x87/austin.git
Assuming you are still interested to see what is happening inside your statistical model while it is training, you can use the command
austin-web -p `pgrep -f my-model.py | head -n 1` -i 10000
As for the TUI, the command line arguments are the same as Austin's. When Web
Austin starts up, it creates a simple HTTP server that serves on localhost at
an ephemeral port.
# austin-web -p `pgrep -f my-model.py | head -n 1` -i 10000
_____ ___ __ ______ _______ __________ _____
____/|_ __ | / /_______ /_ ___ |___ __________ /___(_)______ ____/|_
_| / __ | /| / /_ _ \_ __ \ __ /| | / / /_ ___/ __/_ /__ __ \ _| /
/_ __| __ |/ |/ / / __/ /_/ / _ ___ / /_/ /_(__ )/ /_ _ / _ / / / /_ __|
|/ ____/|__/ \___//_.___/ /_/ |_\__,_/ /____/ \__/ /_/ /_/ /_/ |/
* Sampling process with PID 3711 (python3 my_model.py)
* Web Austin is running on http://localhost:34257. Press Ctrl+C to stop.
If you then open http://localhost:34257 in your browser you will then see a
web application that looks like the following

Note that an active internet connection is required for the application to work, as the d3-flame-graph plugin, as well as some fonts, are retrieved from remote sources.
If you want to change the host and the port of the HTTP server created by Web
Austin you can set the environment variables WEBAUSTIN_HOST and
WEBAUSTIN_PORT. If you want to run the Web Austin web application on, e.g.,
0.0.0.0:8080, so that it can be accessed from everywhere, use the command
# WEBAUSTIN_HOST="0.0.0.0" WEBAUSTIN_PORT=8080 austin-web -p `pgrep -f my-model.py | head -n 1` -i 10000
_____ ___ __ ______ _______ __________ _____
____/|_ __ | / /_______ /_ ___ |___ __________ /___(_)______ ____/|_
_| / __ | /| / /_ _ \_ __ \ __ /| | / / /_ ___/ __/_ /__ __ \ _| /
/_ __| __ |/ |/ / / __/ /_/ / _ ___ / /_/ /_(__ )/ /_ _ / _ / / / /_ __|
|/ ____/|__/ \___//_.___/ /_/ |_\__,_/ /____/ \__/ /_/ /_/ /_/ |/
* Sampling process with PID 3711 (python3 my_model.py)
* Web Austin is running on http://0.0.0.0:8080. Press Ctrl+C to stop.
Write Your Own
Austin's Powers (!) reside in its very simplicity. The "hard" problem of sampling the Python frame stack has been solved for you so that you can focus on processing the samples to produce the required metrics.
If you decide to write a tool in Python, the Austin project on GitHub comes with
a Python wrapper. Depending on your preferences, you can choose between a
thread-based approach or an asyncio one. Just as an example, let's see how to
use the AsyncAustin class to make a custom profiler based on the samples
collected by Austin.
import sys
from austin import AsyncAustin
from austin.stats import parse_line
class MyAustin(AsyncAustin):
# Subclass AsyncAustin and implement this callback. This will be called
# every time Austin generates a sample. The convenience method parse_line
# will parse the sample and produce the thread name, the stack of contexts
# with the corresponding line numbers and the measured duration for the
# sample.
def on_sample_received(self, sample):
print(parse_line(sample.encode()))
if __name__ == "__main__":
my_austin = MyAustin()
my_austin.start(sys.argv[1:])
if not my_austin.wait():
raise RuntimeError("Austin failed to start")
try:
print("MyAustin is starting...")
my_austin.join()
print("The profiled target has terminated.")
except KeyboardInterrupt:
print("MyAustin has been terminated from keyboard.")
As the example above shows, it is enough to inherit from AsyncAustin and
define the on_sample_received callback. This will get called every time Austin
produces a sample. You can then do whatever you like with it. Here we simply
pass the sample, which is just a binary string in the format Thread
[tid];[func] ([mod]);#[line no];[func] ...;L[line no] [usec] to the
parse_line function, which conveniently split the string into its main
components, i.e. the thread identifier, the stack of frames and the sample
duration. We then print the resulting triple to screen.
The rest of the code is there to create an instance of this custom Austin
application. We call wait to ensure that Austin has been started successfully.
The optional argument is a timeout, which defaults to 1. If Austin is not
started within 1 second, wait returns False. If we do not wish to do
anything else with the event loop, we can then simply call the join methods
which schedules the main read loop that calls the on_sample_received callback
whenever a sample is read from Austin's stdout file descriptor.
Conclusions
In this post, we have seen a few profiling options for Python. We have argued that some statistical profilers, like Austin, can prove valuable tools. Whilst providing approximate figures, the accuracy is in general quite high and the error rate very low. Furthermore, no instrumentation is required and the overhead introduced is very minimal, all aspects that make a tool like Austin a perfect choice for many Python profiling needs.
A feature that distinguishes Austin from the rest is its extreme simplicity which implies great flexibility. By just sampling the frame stack of the Python interpreter, the user is left with the option of using the collected samples to derive the metrics that best suit the problem at hand.